Notebook Bab 3 ini punya dua bagian. Bagian Demo tinggal Anda jalankan lalu amati keluarannya; bagian Mini Project berisi soal dan data yang Anda kerjakan sendiri.
Skala fitur numerik memengaruhi model berbasis jarak (k-NN, SVM), tetapi tidak model berbasis pohon. Di sini kita mengukur efeknya pada data yang sama.
Scaling diletakkan di dalam pipeline agar di-fit ulang pada tiap fold cross-validation.
models = {'k-NN': KNeighborsClassifier(),'SVM': SVC(),'Random Forest': RandomForestClassifier(random_state=RANDOM_STATE),}hasil = {}for nama, m in models.items(): tanpa = cross_val_score(m, Xs, y, cv=5).mean() dengan = cross_val_score(Pipeline([('sc', StandardScaler()), ('m', m)]), Xs, y, cv=5).mean() hasil[nama] = (tanpa, dengan)print(f'{nama:14s} tanpa scaling = {tanpa:.3f} dengan scaling = {dengan:.3f}')
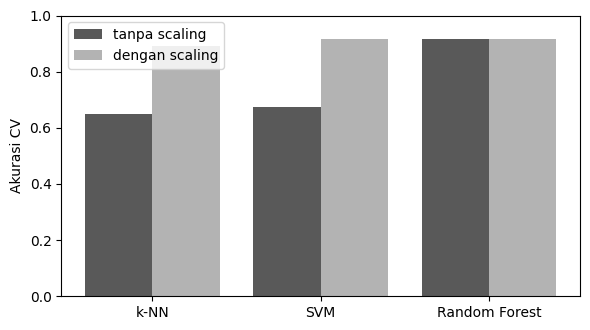
k-NN tanpa scaling = 0.649 dengan scaling = 0.892
SVM tanpa scaling = 0.674 dengan scaling = 0.915
Random Forest tanpa scaling = 0.915 dengan scaling = 0.915
nama =list(hasil.keys())tanpa = [hasil[k][0] for k in nama]dengan = [hasil[k][1] for k in nama]x = np.arange(len(nama))fig, ax = plt.subplots(figsize=(6, 3.4))ax.bar(x -0.2, tanpa, 0.4, label='tanpa scaling', color='0.35')ax.bar(x +0.2, dengan, 0.4, label='dengan scaling', color='0.7')ax.set_xticks(x)ax.set_xticklabels(nama)ax.set_ylabel('Akurasi CV')ax.set_ylim(0, 1)ax.legend()plt.tight_layout()plt.show()
🔎 Amati. k-NN dan SVM melonjak setelah scaling karena keputusannya bergantung pada jarak antar-titik; tanpa penyeragaman skala, fitur berangka besar mendominasi. Random Forest hampir tidak berubah karena pemisahannya memakai ambang per fitur, bukan jarak.
Section 2 - Mini Project
Soal
Anda diberi data numerik dengan distribusi menceng dan skala antar-kolom yang timpang. Bangun pipeline yang menerapkan transformasi yang sesuai (misalnya power transform untuk kolom menceng dan scaling untuk penyeragaman rentang), lalu bandingkan satu model berbasis jarak dengan satu model berbasis pohon.
Luaran: kode pipeline, akurasi CV kedua model, dan 2-3 kalimat analisis kapan transformasi membantu.
Kriteria penilaian: (a) transformasi berada di dalam pipeline; (b) minimal dua keluarga model dibandingkan; (c) analisis menghubungkan hasil dengan sifat model.