Notebook Bab 8 - Reduksi Dimensi & Representasi Laten
Open In Colab
Notebook Bab 8 ini punya dua bagian. Bagian Demo tinggal Anda jalankan lalu amati keluarannya; bagian Mini Project berisi soal dan data yang Anda kerjakan sendiri.
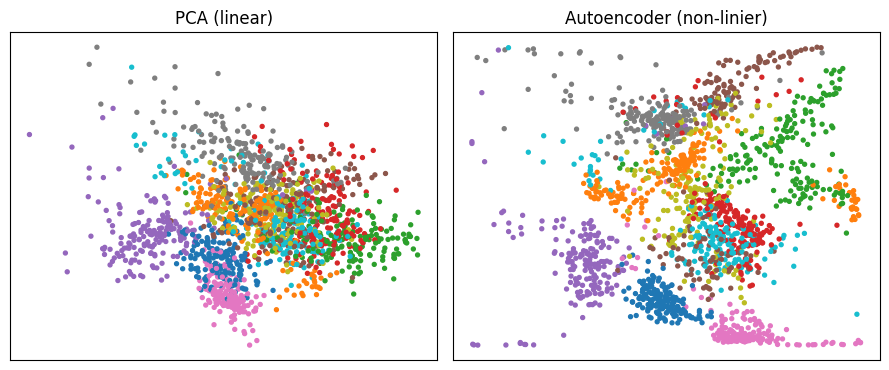
Reduksi dimensi memampatkan fitur. Kita bandingkan PCA (linear) dengan autoencoder (non-linier) untuk visualisasi, lalu mengukur efek jumlah komponen pada akurasi.
🔎 Amati. Di 2D, ruang laten autoencoder yang non-linier cenderung memisahkan kelompok digit lebih tegas daripada PCA yang hanya proyeksi linear. Dua dimensi bagus untuk visualisasi tetapi membuang banyak informasi (akurasi turun jauh); menaikkan ke 20 komponen memulihkan akurasi mendekati fitur penuh. PCA cepat dan transparan, autoencoder lebih ekspresif tetapi lebih mahal.
Section 2 - Mini Project
Soal
Anda diberi data berdimensi 30 (load_breast_cancer, sudah dibakukan). Targetnya klasifikasi biner.
Tugas:
Cari jumlah komponen PCA terkecil yang mempertahankan sekitar 95 persen variance (pakai explained_variance_ratio_).
Latih pengklasifikasi pada representasi PCA itu dan bandingkan dengan fitur penuh.
Tampilkan kurva variance kumulatif.
Luaran: kode PCA + klasifikasi, jumlah komponen 95 persen, dan 2-3 kalimat kesimpulan.
Kriteria penilaian: (a) PCA di dalam pipeline saat mengukur akurasi; (b) pemilihan komponen berdasarkan variance; (c) perbandingan dengan fitur penuh.
# DATA AWAL (jangan diubah)from sklearn.datasets import load_breast_cancerbc = load_breast_cancer()Xb = StandardScaler().fit_transform(bc.data)yb = bc.targetprint('Data:', Xb.shape, '| kelas:', np.bincount(yb))
Data: (569, 30) | kelas: [212 357]
# Kerjakan di sini.# Petunjuk: PCA().fit(Xb).explained_variance_ratio_.cumsum() untuk menemukan ambang 95 persen.