Notebook Bab 9 ini punya dua bagian. Bagian Demo tinggal Anda jalankan lalu amati keluarannya; bagian Mini Project berisi soal dan data yang Anda kerjakan sendiri.
Kualitas fitur diukur dari kontribusinya ke performa. Kita pakai ablation per kelompok dan permutation importance untuk menilai kelompok fitur mana yang penting.
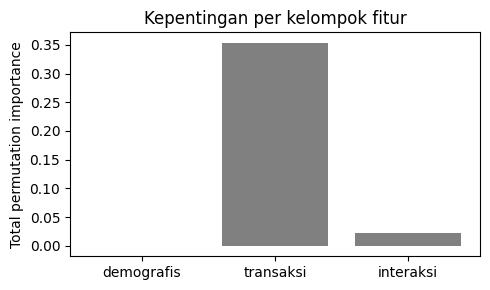
🔎 Amati. Kedua metode sepakat: menghapus kelompok transaksi menurunkan akurasi paling jauh dan kelompok itu juga memuncaki permutation importance, sedangkan demografis nyaris tidak berpengaruh. Ablation mengukur kontribusi satu kelompok terhadap performa; permutation importance mengukur seberapa besar model bergantung pada fitur tersebut.
Section 2 - Mini Project
Soal
Anda diberi data dengan dua kelompok fitur (sinyal dan noise). Targetnya klasifikasi biner.
Tugas:
Tetapkan baseline dengan semua fitur.
Lakukan ablation per kelompok dan laporkan penurunan akurasi.
Bandingkan hasil ablation dengan permutation importance.
Luaran: kode ablation + permutation importance, plus 2-3 kalimat kesimpulan kelompok mana yang penting.
Kriteria penilaian: (a) baseline jelas; (b) ablation per kelompok benar; (c) kesimpulan konsisten antar-metode.
# DATA AWAL (jangan diubah) - dua kelompok: sinyal (kuat) dan noise (kosong).n =2500sinyal = rng.normal(size=(n, 6))noise = rng.normal(size=(n, 6))logit = sinyal @ np.array([1.4, -1.1, 0.9, -0.7, 0.5, -0.4])yq = (rng.random(n) <1/ (1+ np.exp(-logit))).astype(int)Xq = np.hstack([sinyal, noise])grup_q = {'sinyal': list(range(0, 6)), 'noise': list(range(6, 12))}print('Data:', Xq.shape, '| kelompok:', list(grup_q.keys()))
Data: (2500, 12) | kelompok: ['sinyal', 'noise']
# Kerjakan di sini.# Petunjuk: latih model pada subset kolom untuk ablation; sklearn.inspection.permutation_importance untuk pembanding.